
Face Recognition using Eigenfaces
In order to facilitate the recognition of a particular face in a picture, we reparameterize a query picture to a basis of "eigenfaces", or the vectors produced from performing singular value decomposition on a set of training faces. Each of these vectors, when rearrainged into a 2d image, has the appearance of a ghostly face, and tends to accentuate certain charecteristics. Once the query image has been projected to this new coordinate system, we can compare it against existing images, in order to recognize a face.

In the following picture, we show the results of recognition across the entire Yale face dataset. The items have been randomly partitioned into testing set (~30%) and training set (~70%). For each entry in the test set, we show next to it the best match from its closest class of faces. Black lines seperate different test examples. We used k = 25. As can be seen, it does not always give perfect results, but performs very well on average.

The assignment asks several questions that we are to answer in regards to the Yale database of images:
1. How much of the variation is captured by the first 10 principal components? 25?
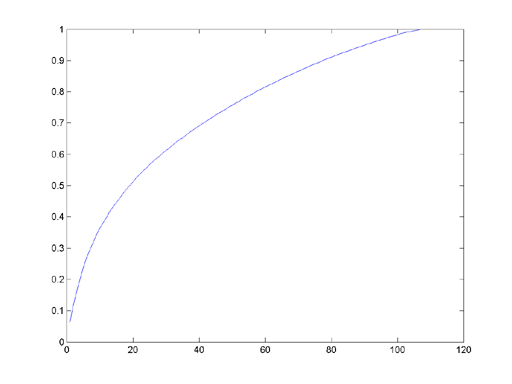
Here we see a chart of the variance captured by each principal componenet, where we assusme that the variance for k componenets is equal to the cumulative sum of those components, divided by the total sum. For k=10, variance=0.363. For k=25, variance = 0.566.
2. How many principle components are required to obtain human-recognizable reconstructions?
In the following figure, each new image from left to right corresponds to using 1 additional principle component for reconstruction. As you can see, the figure becomes recognizable around the 7th or 8th image, but not perfect.

In this next image, we show a similar picture, but with each additional face representing an additional 8 principle components. You can see that it takes a rather large number of images before the picture looks totally correct.

3. How do the results change when excluding the images with glasses?
We show a similar reconstruction to the one above. The images converge to the correct face slightly faster, but not by much.

However, in this next image, we show images where the dataset excludes all those images with either glasses or different lighting conditions. The point to keep in mind is that each new image represents one new principle component. As you can see, the image converges extreamly quickly.

The next example image shows recognition without the glasses-wearing individuals. The results are slightly better, but overall, it seems that glasses do not make a major impact in recognition.
We then show another example of recognition where only the normal lighting and no glasses images are used (except for the three people that are always wearing glasses). The recognition is perfect.

4. Try some recognition experiments on subsets of the database corresponding to changes in lighting and changes in expression. Which category of variations is easier to accommodate? It is much easier to accomodate a change in expression. Presumably this is because the relative intensities of the pixels are very similar between images of different expressions, while those with different lightings display very different intensitites. Put another way, the eigenfaces technique is robust against local changes, but not to global changes. Consider the following examples, where the lighting has been varied.

About half of all of the classifications are wrong (9 of 16 correct). Compare this to the following image, where the expressions are different, and almost all of the classifications are correct (23 of 26 correct).

5. Can you recognize non-faces by projecting to orthogonal complement?
Yes, we can. The key is that when non-face images are projected to the eigenfaces subset, and then reconstructed, they will not resemble the original images (they will look like faces). Images that are faces, however, will resemble the original face to some degree. We can see this in the following example.

The two face images on the left clearly resemble their corresponding reconstructions below. From this, we know that they are faces. The others, which are not faces (real human faces, at least) do not have reconstructions that match the original. This allows us to distinguish faces and non-faces.
- EigenScript.m Main routine that performs Eigenface analysis and shows a bunch of figures, as presented above.
- readyalefaces.m Reads the Yale face dataset from a directory, and puts then into a structure labeled by their types.
- centerfaces.m Given an array of images, will allow the user to select the center of the face, and will cut it out. This allows all the images to be the same size, and to be focused on the correct area of interest.
- viewfaces.m A simple image viewer that allows scrolling through the Yale dataset in 2 dimensions
- tightsubplot.m A helper routine that makes subplot lie immediatly next to each other, without borders.
- meanface.m A helper routine averages the faces.
You can find the dataset here, and find others from the original assignment.
You may use this code however you wish, for either commercial or non-commercial projects. If you find it useful, please drop me a line, I'd love to hear about it.